Solr Automation
Author : Gaurav Jham & Dheeraj Kumar Jha
(Image Credit: https://lucene.apache.org/solr/)
What is Solr?
Solr is an open-source enterprise-search platform, written in Java, from the Apache Lucene project. Solr is highly scalable, ready to deploy, search engine that can handle large volumes of text-centric data.The purpose of Apache Solr is to index and search large amounts of web content and give relevant content based on search query.
Its major features include full-text search, hit highlighting, faceted search, real-time indexing, dynamic clustering, database integration, NoSQL features and rich document (e.g., Word, PDF) handling.
Need for Solr Automation
In Solr, to verify data for each module manually is a tedious task. It requires great manual effort to check for different datasets and scenarios.
As data in many modules in Shiksha is fed through Solr. So to reduce that manual effort and to make testing effective, we need to integrate Solr in our scripts and verify data of each module through automation.
Modules automated in Shiksha Automation Suite :
- Shiksha Reviews.
- Predictor Data Validation.
- Scholarship Data on Study Abroad Pages.
Important points to keep in mind before Automating Solr
Although there are no prerequisites for Automating Solr at Code level, there are still some prerequisites
- One should have proper knowledge of Solr Queries & how to pass data in Solr Queries. One should also be aware of Faceting Queries which helps in actual filtering of data & count based on the filter .
- Faceting Range Queries is also one of the important queries while fetching the data.
Querying Data from Solr
- Solr Data Queries — Apache Solr also provides the facility of querying it back as and when required. Solr provides certain parameters using which we can query the data stored in it.
- Faceting Queries — Faceting in Apache Solr refers to the classification of the search results into various categories .It returns the number of documents in the current search results that also match the given query.Faceting commands are added to any normal Solr query request, and the faceting counts come back in the same query response.
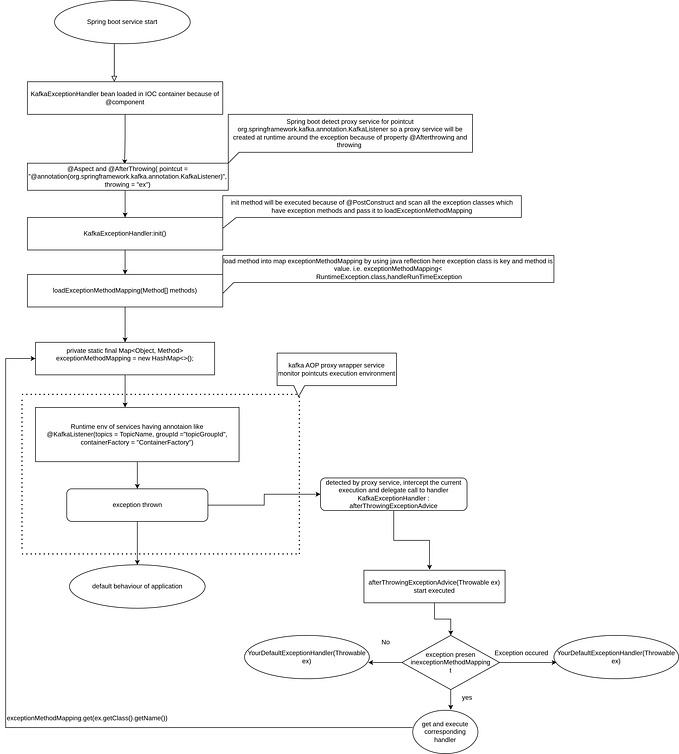
SolrJ
Apache SolrJ is a Java-based client for Solr that provides interfaces for the main features of search like indexing, querying, and deleting documents.
All requests to Solr are sent by a SolrClient. SolrClient’s are the main workhorses at the core of SolrJ. They handle the work of connecting to and communicating with Solr, and are where most of the user configuration happens.
Requests are sent in the form of SolrRequests, and are returned as SolrResponses.
Maven Configuration
Shiksha automation project is a maven project. So to use SolrJ in the project, we needed to add the following maven dependency in pom.xml file.
Dependency can be found on maven central.
Implementation in Automation Project
Following are the steps to connect to Solr in script through SolrJ Java API
- We need to have a Solr host to set up a Connection. For Solr Connection, first we need to create SolrClient , which is actually used to send requests to Solr Server. For this, we require a HTTPSolrClient which interacts directly to Solr Server via HTTP.
- Then, we need to create a SolrQuery, which represents a collection of name-value pairs sent to the Solr server during a request.
- Then, We create a QueryResponse object which will store the response and the output of the Solr Query . While fetching response from request , We need to throw SolrServerException (which may occur while communicating with Solr Server) .We can parse this Response and store it in a String object.
Below is the code snippet for the same.
Querying in SolrJ
SolrClient has a number of query() methods for fetching results from Solr. Each of these methods takes in a SolrParams, an object encapsulating arbitrary query-parameters. And each method outputs a QueryResponse, a wrapper which can be used to access the result documents and other related metadata.
Same has been shown in the above screenshot.
Benefits after Automating Solr
- Able to verify over large data set in less time
- Manual effort got reduced
- Chances of finding irregularities are high. It leads to minimal data issues in the system.