Moving to Microservices Architecture
Author: Ankit Bansal
In this blog, we will be talking about Shiksha backend stack migration from Monolithic Architecture to Microservices Architecture. The benefits of Microservices Architecture is already mentioned in the previous blog
Requirements
Before implementation, we had to make sure to create the backend Architecture such that we can deliver the following:

Performance: We need to achieve high google page speed scores and one of the very critical factors in achieving this is Backend API Response time. Also, since we were also planning to move to PWA, faster APIs means an increase in user-perceived performance during client-side rendering. We have set the target to achieve 100ms average response time, which will be 3–4x faster than our previous monolithic Architecture(~300–400ms).
Scalability: Another challenge that we have to solve, is that we want a system which has a horizontally scalable architecture if needed. We should be able to auto-scale, on-demand/ on sudden traffic peaks. Our scaling also depends on other resources such as a database connection. So for example, suppose we have a database server that can provide 500 DB connections, Now for each service instance, if we need 50 DB connections, we can scale up to 10 service instances only.
High Availability: This is another critical challenge that needs to be taken care of. We started with the aim of 5 nines’ or at least 4 nines’ availability. To ensure this, we need to ensure the following things :
- No SPOF(Single Point of Failure): Any service of the application can go down anytime due to hardware failure. So any failure should not prove fatal to our architecture. So need to ensure redundancies for all the components used in the architecture.
- Graceful Degradation: We want our systems to be fault-tolerant and keep working even if part of the system goes down. It is an essential aspect for us as we have pages with multiple widgets, and we do not want pages to throw errors even if a single widget fails.
- Retries(With Exponential Backoff): The idea behind using exponential backoff with retry is that instead of retrying after waiting for a fixed amount of time, we increase the waiting time between retries after each retry failure. Retries with this approach give the service some breathing time so that if the fault is due to service overload, it could get resolved faster.
Architecture

Following is the Shiksha Backend architecture:
- API Gateway / Facade layer: API Gateway is the entry point for all the APIs. It is the standard while creating the microservice architecture. The Facade layer hides the complexities of the system and provides an interface to the client using which the client can access the system. No business logic is written at this layer. Its job is to call the service layers and aggregate the data.
- Service Layer: This is where the actual business logic lies. Services are stateless and interact with data sources
- Load balancers: As already mentioned, our application does not have any SPOF. Hence we have load balancers, which are handling load-balancing of Gateway / Service layer.
- API Caching Layer: Since most of our APIs are content-driven, we have also added the API Caching Layer which caches the response(JSON) for our APIs with some specific TTLs. We are also purging the caches as soon as any data gets changed, to update the data on-site in real-time. API Caching is crucial because firstly it helps us significantly to reduce the response time for our APIs and secondly we can handle more load and hence more traffic with less infra.
- Data layer: This is the data layer like our database like Mysql, Cassandra our caches server, our Search tools(Solr, ElasticSearch, etc.)
Tools & Framework
Before beginning this micro-service architecture, we were working on PHP. But with this architecture, we have decided to stop using PHP any more.
So we have explored various options: Go, Scala, Java, Python. After some research, we have found JAVA to be best suitable for our purpose. The primary reasons include the support for multi-threading, great community support plus regular upgrades, support for micro-services supporting ecosystem frameworks like Spring boot, Jersey, Apache CXF.
But we don’t need to write all our services in JAVA. With this architecture, services can be language agnostic. We have a few services written in python.
Next, we have to figure out the framework which we will be using. After some research, we have found Spring boot(with Maven) to be most suitable for our use. Plus we have also used JPA with Hibernate for the Database interaction.
Starting with a very small team, we have brainstormed and listed down various questions which we need to answer :
- Centralized Configuration: This is the basic need for architecture. We knew from the start that we would have different services which be having some common configuration and we do not want to store the same config with individual services to make them redundant. Hence we need to figure out a way, so we can keep some global configuration so that all services can access that config.
- Storing Local Maven Artifacts: We have decided to use Maven. Apart from the open-source libraries, we have created some in-house libraries which are required for building the code. So we need to set up our maven repository locally and store/fetch our local artifacts from that repository. We have used JFrog for this purpose.
- Deployment: Currently, we are following Multiple Service Instances per Host / VM. But we are currently working towards containerizing the whole application. So we are moving towards Single Service per container. For deployment, we are using Jenkins pipelines.
- Service to Service Interaction: There are two ways by which services can communicate with each other, Synchronous communication and Asynchronous communication. Synchronous communication is needed when we need to use the response of the calling API, and asynchronous is needed when we need to perform some action like sending a notification, logging something, etc., which can run independently in the background. Currently, we are using both ways of communication. For Async communication, we are using Kafka Queues. For synchronous communication, we are using Open Feign(Feign client)
- Distributed Tracing: Microservices has some pros, but it also comes with some cost. In a monolithic architecture, we have to deal with just one project, so identifying bottlenecks in applications is very easy. We just to place logs and read them. But in a micro-services architecture, for one front-end page, there can be multiple API Calls. So to identify the bottlenecks meaning collating the logs of all the services and be able to link the logs of a particular request. We have started with Zipkin to solve this challenge.
- API Security: Security is always important. We need to ensure that our APIs are secure. This includes Authentication, Authorization, Identifying and serving only known clients.
- API Versioning: Since we are also supporting Mobile App, we need to support versioning of our APIs. Point to be noted here is that we only increment the version of our APIs when we need to do any breaking change. Breaking change means changing the data for the particular field or deleting the particular field from the response. Adding any data is not a breaking change, so we do not upgrade the API version in this case.
- How to achieve such high performance: This is one of the biggest challenges that we have to solve. We have to ensure many things about this. This includes all the Data sources(DB, Solr, ElasticSearch, etc) calls to be optimized, a number of API calls that are being made / number of data sources call being made. Apart from this, we need to follow the JAVA best practices to keep sanity across the code. The important thing is that we have to make sure to write the code so that we should be able to make parallel calls while calling other services. So we have decided to write the aggregation layer(facade layer) in the Reactive Programming style. We have preferred concurrent programming over parallel programming.
- Graceful degradation: Reactive programming provides some error handling functions, which helped us to achieve this. Just while calling API(as an event), we need to add the error handling functions such as onErrorReturn(which usually is some empty collection/DTO).
- Exception Handling: This is also needed because it is not an excellent approach to put try-catch everywhere where we want to catch exceptions. Also, we have use-cases where we want to throw some specific response code on errors as request validation failed, incorrect resource id, etc. So we have also solved this using common exception handling. We have used AOP(Aspect Oriented Programming) for this.
- Service Discovery: This is very important if we want to auto-scale the applications. We have explored Eureka Server with Ribbon client and Consul with HaProxy for this. With service discovery client side load balancing is used. Currently, we are not using Service discovery, but this is a Work in progress, and very soon, we will be using service discovery instead of server-side load balancing.
- Monitoring: We need to ensure whether everything is working fine or not. We also want to monitor every part of the component proactively. The aim of this monitoring is not only to fix things once they are broken but to get the monitoring alerts before the system actually breaks but starts to show signs of breaking (like consistent increase in server load, continuous exceptions. increase in pool sizes, heap size alerts, etc.). Currently, we are monitoring JVM metrics, GC metrics, Database connection pool metrics, Application Status codes / Response codes, response time, exceptions that are coming. Everything is being monitored, and stats are available in real-time.
- Common Util Lib: If we have something common for all the services, we don’t want to duplicate it inside each service. In Shiksha, we keep a separate project called util-lib. Each core services have to add util-lib as a dependency.
Result
As of today, the majority of our pages are using APIs which are written on the new Architecture. The performance benchmarks that we have set for ourselves, we have successfully achieved. The majority of APIs that we have written are responding within 100ms(daily average).
We have also done some load testing, sharing the results. This is with 2 instances(8 Core 16GB) and MySQL pool of idle 10 and max 20.
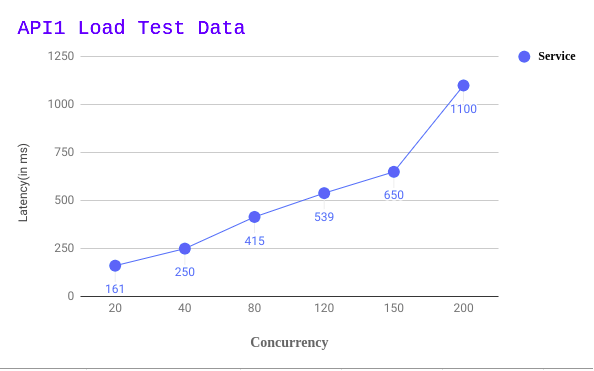
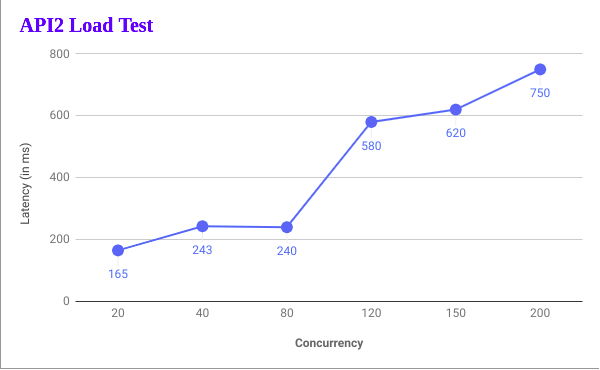
Also Read
