Reactive Programming
Author: Garvit Gupta
What is Reactive Programming?
Reactive programming is a programming paradigm that promotes an asynchronous, non-blocking, event-driven approach to data processing.
Asynchronous programming is a means of parallel programming in which a unit of work runs separately from the main application thread and notifies the calling thread of its completion, failure or progress
A non-blocking architecture is based on method calls that, while they may execute for a long time on the worker thread, do not block the calling thread.
Event-driven programming is a programming paradigm in which the flow of the program is determined by events such as user actions (mouse clicks, key presses), sensor outputs, or messages from other programs or threads
Advantage of reactive programming over old thread-based programming:
In the early days of Java, threading abstraction was a major advantage over other programming languages of that time. It still offers easy access to parallel programming and synchronization to developers today. Web frameworks could then be implemented very easily on this basis, since the binding of a web request to a thread in the servlet API made it possible to process a request virtually imperatively, without worrying about concurrency and synchronization. Before there was Tabbed Browsing and Ajax, one could also be quite sure via (web page) design that two requests of the same user session were never executed in parallel, which meant that the normal developer had practically no need to worry about parallel processing at the user session-level.
The above-mentioned implementation of the Java threading abstraction currently has a serious disadvantage: Java threads are implemented as operating system processes so that every thread switch means a (very expensive) context switch in the operating system. At a time when web applications only had to process several thousand requests per minute, this was not a problem. In the meantime, however, the requirements for web applications have become significantly higher. Rising user numbers and more interactive SPAs (with more client-server communication) mean that today’s enterprise applications have to process noticeably more requests per minute than 15 years ago. The model in which a request is processed by an operating system thread reaches its limits. Especially when the request is blocked in between, e.g. when a database query is executed or when another microservice is called.
The degree of parallelism is significantly higher than at the time when the decision was made to implement Java threads as operating system processes. The requests and the code executed in them are now much shorter. This does not match the expensive context switches of the operating system processes.
This is where Reactive Programming comes in. The paradigm is exactly the opposite of the Java threading model. While the threading model tries to keep asynchronicity away from the user (“Everything happens in one thread”), in Reactive Programming asynchronicity is the principle. The program flow is seen as a sequence of events that can occur asynchronously. Each of these events is created by a Publisher. It does not matter on which thread the Publisher creates it. In a reactive application, the program code consists of functions that listen to this asynchronous publication of events, process them and, if necessary, publish new events.
This approach is particularly useful if you are working with external resources such as a database. In a classic Enterprise Java application, the system sends an SQL statement to the database and blocks until the database returns the result. With Reactive Programming, the statement is executed without waiting for the result. A method to submit a database query immediately returns a Publisher instead of blocking. The caller can register with this publisher to be informed when the database result is available. The result of the database is later published as an event on the Publisher.
Reactive programming involves modelling data and events as observable data streams and implementing data processing routines to react to the changes in those streams. In the reactive style of programming, we make a request for the resource and start performing other things. When the data is available, we get the notification along with data in the form of a call back function.
In the callback function, we handle the response as per application/user needs.
Publisher Subscriber Pattern

The basic building block of Reactive Programming is a sequence of events, and two protagonists, a publisher and a subscriber to those events. Communication infrastructure receives messages from publishers and maintains subscribers’ subscriptions.
Publisher: Publishes messages to the communication infrastructure
Subscriber: Subscribes to a category of messages
Reactor Core Publisher-Subscriber Model
An Observable is a producer of multiple values, pushing them to subscribers. We subscribe to an Observable and we will get notified when the next item arrives onNext, or when the stream is completed onCompleted, or when an error occurred onError.
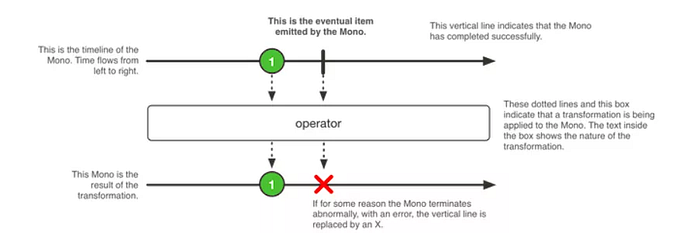
Mono
A Mono is a specialized Publisher that emits at most one item and then optionally terminates with an onComplete signal or an onError signal. In short, it returns 0 or 1 element.
Flux
A Flux is a standard Publisher representing an asynchronous sequence of 0 to N emitted items, optionally terminated by either a completion signal or an error. These 3 types of signal translate to calls to a downstream subscriber’s onNext, onComplete or onError methods.
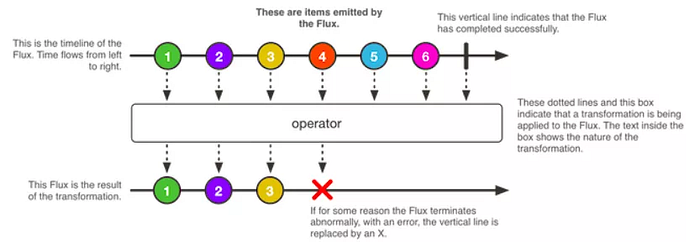
Subscribing to Streams
When we write a Publisher, data does not start pumping into it by default. By the act of subscribing, we tie the Publisher to a Subscriber, which triggers the flow of data in the whole chain. This is achieved internally by a single request signal from the Subscriber that is propagated upstream, all the way back to the source Publisher. To make the data flow we have to subscribe to the Flux using one of the subscribe() methods. Only those methods make the data flow. They reach back through the chain of operators you declared on your sequence (if any) and request the publisher to start creating data.
Reactive Programming Application
The below example demonstrates asynchronous (zipping multiple sources together to make calls to multiple services asynchronously), non-blocking (subscribing sources to schedulers, not on the main thread), and event-driven (using blockFirst so as to signal) nature of Reactive Programming.
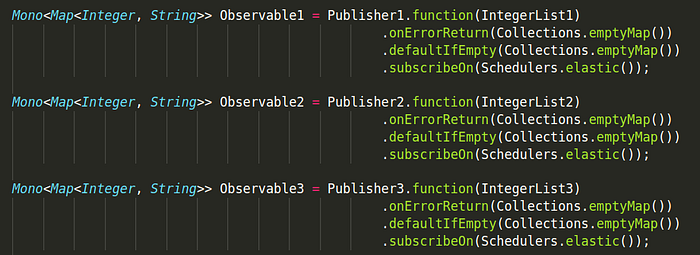
Publisher 1, Publisher 2, Publisher 3 are three different Publishers which could be three different APIs wrapped with Mono::fromCallable function. What we can do is use these three publishers and define where to subscribe to this publisher. We also define what happens if any error occurs using onErrorReturn method and what would be the default value in case mono completes without any data using the defaultIfEmpty method. Now, we have 3 Mono’s which will output the data of the Publisher when the subscription occurs. In Reactor, the execution model and where the execution happens is determined by the Scheduler that is used, in the above case it is Schedulers.elastic.
The Schedulers class has static methods that give access to the following execution contexts:
- The current thread (Schedulers.immediate()).
- A single, reusable thread (Schedulers.single()).
- An unbounded elastic thread pool (Schedulers.elastic())
- A fixed pool of workers that is tuned for parallel work (Schedulers.parallel()). It creates as many workers as you have CPU cores.
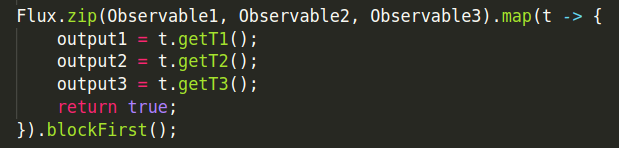
Flux Zip is used to zip these mono’s together, that is to say wait for all the sources to emit one element and combine these elements once into a Tuple. The operator will continue doing so until any of the sources completes. Map method transforms the items emitted by this Flux by applying a synchronous function to each item which is defined by t. Errors will immediately be forwarded and blockFirst method is called to block indefinitely until the upstream signals its first value or completes. In the above case, it is 3 streams, which emits 0 or 1 element, so in other words, blockFirst waits for all streams to emit an element and since these are subscribed on parallel threads, the execution is non blocking, separate from the main thread.
Advantages of Reactive Programming
If we need data from multiple streams and we call these services on the main thread and wait for the response from each of the services, that is, synchronous, blocking nature, the time taken to get the data from all the streams will be the sum of the time taken by the individual stream.
Whereas, by using reactive programming and zip method to easily combine the results of several Mono gives the great benefit that the execution of zip method will last as much as the longest Mono not the sum of all the executions. Thus, reducing the response time of API drastically.

How we leveraged Reactive Programming in Shiksha
In Shiksha, we have more than 15 distinct modules interacting with each other. All these modules have their own service driving the module. But when it comes to users facing a Shiksha Web page it does not belong to one module wholly. A Shiksha web page can be categorized into Institute/university/course/exam/article listing page broadly. For example, let’s take an Exam Page. An exam page on Shiksha consists of data from Exam service, AnA Service, Article Service & Search Service mainly. Now to get this data we use Flux in our aggregator service to call respective services and get data.
We have used Flux.zip , Flux.map, and Flux.blockFirst() in our code.
Flux.zip Used to combine all observables sources into one Flux. This will return a zip flux which contains all sources which will emit one value.
Flux.map Used to transform items emitted by the flux synchronously. Here our publishers will emit values, which in turn will be processed synchronously. Here we have a DTO which is carrying responses from the publishers.
Flux.blockFirst We have called blockFirst() so that we can wait indefinitely until the upstream signals its first value or completes. Here in our case, we will wait for all the publishers to emit value.
One thing to note here is that we have wrapped our publishers with Retry and Timeout wrappers. This we have done to ensure that in case if any of our publishers face issues like server unavailable or timeout, how are we going to deal with it. So, in our case, we have specified that our Mono will throw a timeout exception after 4 seconds if it is not able to emit a value. And it will try 3 times to get the value.
Happy Coding!!!