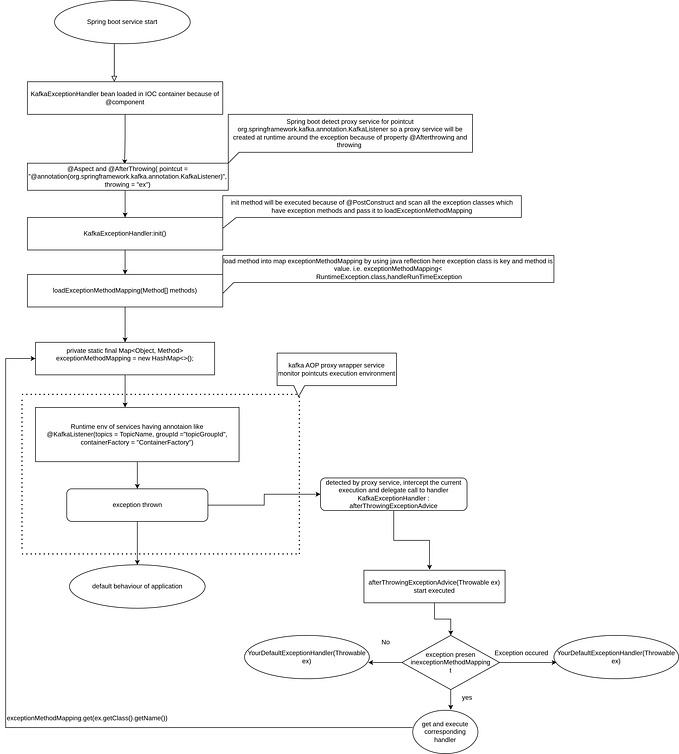
Rate Limiting on Kafka
Author: Abhinav Shankar Pandey
In Shiksha, we deliver lots of leads from different products to more than 200 distinguished clients. We deliver leads in near real-time at the time of lead creation.
Now, since we deliver lots of leads there are high chance that a Rate limit will occur at the client’s service level. For this client always implement HTTP Status 429 at service level.
Problem: The previously implemented system has the following challenges:
- It would consider the lead as a Rate Limiter only if HTTP Status Code: 429 is received.
- It would add the same amount of wait for the lead received in the header “Retry-After“.
- For every lead, it would wait only when the packet is eligible for consumption.
Out of all mentioned above, the main concern in this approach was the how wait is being implemented on the packet. Because, for every packet in the Retry Queue, wait was implemented only when the said packet would arrive at the consumer. To get more clarity on this consider an example.
If packet A has to wait for 3 seconds and packet B has to wait for 5 seconds both went to the queue one after the other. At the consumer level when packet A arrives it will wait for 3 seconds then it will get processed and then packet B will arrive which will wait for 5 seconds. If you see for how much time did packet B wait? It waited for the amount of time packet A waited plus the amount of time B itself waited at the consumer level. This amounted to 8 seconds of wait on packet B. But in original B has to wait for only 5 seconds.
Then comes how to solve this problem
Solutions: We explored different solutions.
- Go RabbitMQ Way:
One solution was to use RabbitMQ which provides a delay queue. This could have solved the problem to some extent.

But we did not want to introduce RabbitMQ just for this sake. Because it would cost us 2 things in major.
- Change the implementation of only 1 specific Queue(i.e. Rate Limiter Queue) to move it to RabbitMQ from Kafka.
- Just for this sake introduce RabbitMQ and introduce the maintenance cost to the system.
- Also, when working on a large scale(this we generally face during peak season), Kafka provides a more scalable solution than RabbitMQ.
2. Schedule a Periodic Job
The other solution we thought of having a scheduler job. In this approach, we thought of queuing packets(leads data) in persistent storage along with the time when the packet was created and the amount of delay needed to be applied to the packet. Then schedule a Job which will check every minute when a packet is eligible for processing. At first, this looked fine solving our problem but it too has its drawbacks as below:
- The scheduler can be run via cron at a minimum interval of 1 minute. It means any amount of delay which will be between 0–60 seconds will be processed at 60th Seconds of the clock time. And same will happen for the consecutive time window of multiples of 60s.
- Running a cron job required writing more code, getting it tested, maintaining it, monitoring it and then keeping track of all records.
- The cost of keeping these packets in persistent storage requires more disk size.
Though we could have taken up this option by optimizing #2 and #3 mentioned above, #1 was a serious drawback which we could not afford.
3. Explore Kafka, Find Possibilities:
One solution was already implemented. It was solving the problem of Handling HTTP Status Code: 429.
We thought why not go ahead and improve this implementation and build the solution on Kafka itself?
We went ahead and said let’s push the message to Kafka and keep rotating the message to the same Kafka Queue(Rate Limiter) until the message is eligible for delivery.
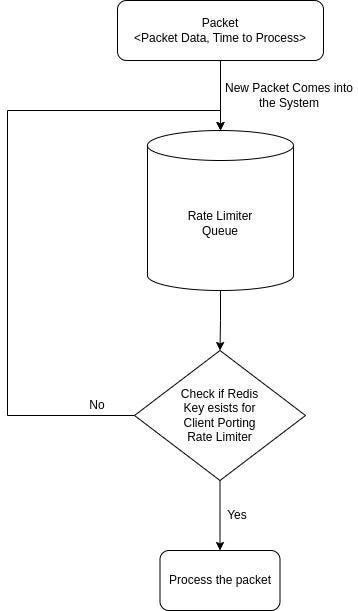
At first hand, this looked good to us. This solution was solving the problem and at the same time was also addressing the drawbacks of the other 2 explored options.
Implementation: We went ahead and implemented the Rate Limiter Kafka Queue with re-queue until eligible for delivery mechanism. We got our code tested in the test environment. Everything worked well for us. We pushed the build to production. On production as well the code was executed well. It passed all test cases. We got the code tested for Rate Limiters as well. For some of our top clients the Rate Limiters are quite often and it worked well for them as well. Nothing suspicious was noted.
Catastrophe: All went well until one fine day we received lots of Rate Limiter, not a usual event for us. And boom. Things started getting slowed down. The problem was not in application. The application was running smoothly. Deliveries were happening smoothly. Clients were getting leads delivered in real-time. Then what was the problem? Our Kafka disk started getting more than 94%-95% fill alerts. What was causing this?
Analysis: How suddenly does our Kafka disk start getting written with so much data? We analyzed the situation and the problem. Our Rate Limiter was writing too many times. Writing? Yes. Kafka queues the data in the append-only file and maintains the offset for the consumer until where it has been read. Then this data in the append-only file is maintained for the said time we configured as a retention period in Kafka Queue.

We checked and found that the retention period on our Kafka Queues is either 4 days or 7 days by default. We keep this number big because just in case we are not able to process any record or the records of some period are wrongly processed, we will able to make it up for it if we have retained the messages in Queue.
Fine Tuning the implementation: So what can we do here? We thought first to reduce the retention time of the Rate Limiter Queue. We did it. And yes, the disk freed up. But still, our Rate Limiter was writing too much. It would write thousands of times in a few seconds. So reducing the retention time gave us a breather but we knew this was not the solution. And it can break anytime. We went to the design board again and re-looked what we can do here. And then we cracked a solution.
Let the packet expire with the time: What does this mean?
For every packet that goes into the Rate Limiter will carry with itself the tobeprocessedAt time value. This was not a big change for us. Why? Because until now we had already built the common data packet for the entire delivery system. Which meant that adding this data value was just a very small task to do. Next, we made changes at the consumer level. We computed the difference between the current time and the tobeprocessedAt value. If it is a positive value then that means there is some delay which is to be done and the consumer thread would go to sleep for exactly that duration. Or Else, if the value is zero or negative then the data is ready for consumption and that would get passed to the next level of processing.
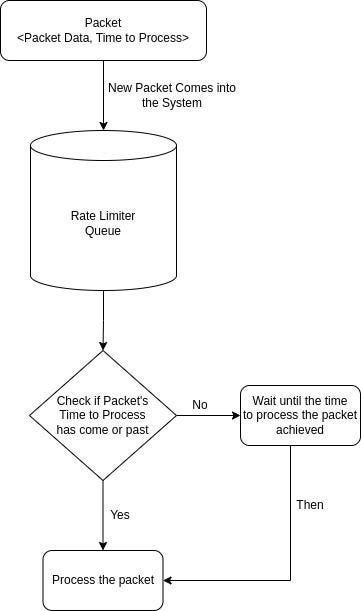
We tested the code. And pushed it to production. Voila! Things worked well for us.
We tested the code. And pushed it to production. Voila! Things worked well for us.
Challenges with the approach: This solution is working well for us. But this too has its challenges. Below are the mentioned ones:
- A packet with lower tobeprocessedAt arrives after the packet with higher tobeprocessedAt will have to wait for this higher value packet.
- What if Kafka disconnects from the consumer due to the consumer’s sleep thread?
The problem mentioned in #1 can be solved by dividing the Rate Limiter Queues into broader Queues like the below:
- Rate_Limiter_3: Any message with a waiting time of less than equal to 3 seconds can be added to this queue.
- Rate_Limiter_5: Any message with a waiting time of greater than 3 seconds and less than equal to 5 seconds can be added to this queue.
- Rate_Limiter_7: Any message a waiting time of with greater than 5 seconds and less than or equal to 7 seconds can be added to this queue.
- Rate_Limiter_10: Any message a waiting time of with greater than 7 seconds can be added to this queue.
These broader Queues can be decided case by case. Consumer code can be kept the same. Only instances of Consumers will be required. Since consumers are just redirecting the packets to relevant services it can be easily assumed these consumers will be very light in processing. Always, the highest nth group queue will have the possibility of writing to the Kafka Queue that too at an interval n time unit.
To solve the problem of Kafka disconnecting from the consumer, we can keep the sleep time at a lower value. This will make the packet again eligible for writing back to the queue but will still have very less writes compared to the re-queue without delay.
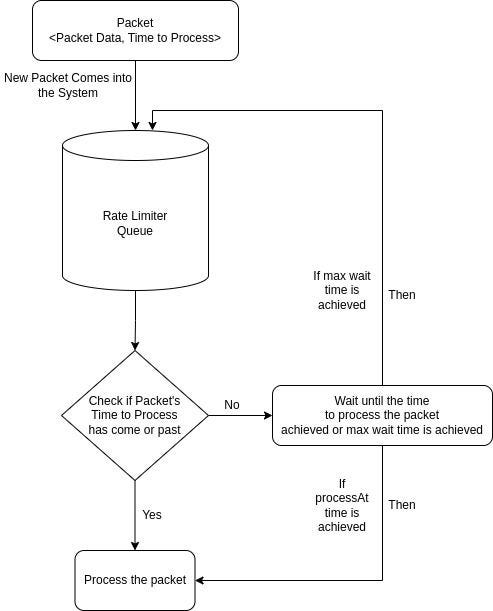
Finally, we froze our implementation of this. This worked for us solving all possible cases and achieving all tech challenges.
- Lowest Re-writes to Queue.
- Proper wait time for every eligible packet
- Very Low I/Ops for Kafka
- No need to introduce any extra application for delay
- 100% use of current infra
- More flexibility in optimizing and controlling the inflow of packets in Kafka
Though at first hand this looks like a very straightforward solution, it is not. It took us going through the problem again and again, and trying to build the solution through iterations to achieve an optimized approach. We’re still monitoring the application and will update this doc if we find any challenges or if we improve on this approach to achieve a better solution.
Until then, keep solving the problems !!